



棋牌问答 求通俗解释下bandit老虎机到底是个什么东西
发布日期:2022-03-14 13:15 点击次数:70
这篇回答节选自本人在知乎专栏上正在持续更新的一个系列文章的引子:要了解MAB(multi-arm bandit),首先我们要知道它是强化学习(reinforcement learning)框架下的一个特例。至于什么是强化学习:我们知道,现在市面上各种“学习”到处都是。比如现在大家都特别熟悉机器学习(machine learning),或者许多年以前其实统计学习(statistical learning)可能是更容易听到的一个词。那么强化学习的“学习”跟其它这些“学习”有什么区别呢?这里自然没有什么标准答案,我给这样一个解释(也可见Sutton & Barto第二章引言):在传统的机器学习中,主流的学习方法都是所谓的“有监督学习”(supervised learning),不管是模式识别,神经网络训练等等,你的分类器并不会去主动评价(evaluate)你通过获得的每个样本(sample)所进行的训练结果(反馈),也不存在主动选择动作(action)的选项(比如,可以选择在采集了一些样本之后去采集哪些特定的样本)。意思就是,在这些传统的机器学习方法中(实际上也包括其它无监督学习或者半监督学习的很多方法),你并不会动态的去根据收集到的已有的样本去调整你的训练模型,你的训练模型只是单纯被动地获得样本并被教育(instruct,作为对比,active learning主要就是来解决这一问题的)。而强化学习主要针对的是在一个可能不断演化的环境中,训练一个能主动选择自己的动作,并根据动作所返回的不同类型的反馈(feedback),动态调整自己接下来的动作,以达到在一个比较长期的时间段内平均获得的反馈质量。因此,在这个问题中,如何evaluate每次获得的反馈,并进行调整,就是RL的核心问题。这么讲可能还比较抽象,但如果大家熟悉下围棋的AlphaGo,它的训练过程便是如此。我们认为每一局棋是一个episode。整个的训练周期就是很多很多个epsiode。那么每个episode又由很多步(step)构成。动作——指的就是阿法狗每步下棋的位置(根据对手的落子而定)反馈——每一次epsiode结束,胜负子的数目。显然,我们希望能找到一个RL算法,使得我们的阿法狗能够在比较短的epsisode数目中通过调整落子的策略,就达到一个平均比较好的反馈。当然,对这个问题来说,我们的动作空间(action space,即可以选择的动作)和状态空间(state space,即棋盘的落子状态)的可能性都是极其大的。因此,AlphaGo的RL算法也是非常复杂的(相比于MAB的算法来说)。至于什么是MAB/老虎机问题:我们先考虑最基本的MAB问题。如上图所示,你进了一家赌场,假设面前有  台老虎机(arms)。我们知道,老虎机本质上就是个运气游戏,我们假设每台老虎机
台老虎机(arms)。我们知道,老虎机本质上就是个运气游戏,我们假设每台老虎机  都有一定概率
都有一定概率  吐出一块钱,或者不吐钱( 概率
吐出一块钱,或者不吐钱( 概率 )。假设你手上只有
)。假设你手上只有  枚代币(tokens),而每摇一次老虎机都需要花费一枚代币,也就是说你一共只能摇 次,那么如何做才能使得期望回报(expected reward)最大呢?这就是最经典的MAB场景。那么问题的核心是什么呢?自然,我们应该要假设 们是不太一样的(不然怎么摇都一样了),即有一些老虎机比较“好”(更容易吐钱),有一些则比较“差”(不太容易吐钱)。回到RL的框架,我们的动作是什么?即每次摇哪台老虎机。我们的反馈呢?即我们摇了某台特定的老虎机当回合可以观察它吐了钱没有。这里当然还有个重要的统计学/哲学问题:即我们是贝叶斯人(Bayesian)还是频率学家(frequentist)。对贝叶斯人来说,我们在一进入赌场就对每台老虎机扔钱的概率 就有一个先验分布(prior distribution)的假设了,比如一个很常见的我们可以用Beta分布。如果我们认为大概率 都应该是0.5,即对半开,而不太可能出现一些很极端的情况,我们就可以选择Beta(1,1)分布作为我们的先验分布。然后在我们真正摇了老虎机之后,根据相应的反馈,我们就可以调整 们相应的后验分布(posterior distribution)。比如如果某台机器摇了四五次一直吐不出钱,我们就应该将这台机器的吐钱概率的分布往左推,因为它的 大概率应该是小于0.5的。那么,你的任务便是要在有限的时间内找出 后验分布比较靠右的那些机器(因为他们更容易吐钱),并且尽可能多的去摇这些比较赚钱的机器。
枚代币(tokens),而每摇一次老虎机都需要花费一枚代币,也就是说你一共只能摇 次,那么如何做才能使得期望回报(expected reward)最大呢?这就是最经典的MAB场景。那么问题的核心是什么呢?自然,我们应该要假设 们是不太一样的(不然怎么摇都一样了),即有一些老虎机比较“好”(更容易吐钱),有一些则比较“差”(不太容易吐钱)。回到RL的框架,我们的动作是什么?即每次摇哪台老虎机。我们的反馈呢?即我们摇了某台特定的老虎机当回合可以观察它吐了钱没有。这里当然还有个重要的统计学/哲学问题:即我们是贝叶斯人(Bayesian)还是频率学家(frequentist)。对贝叶斯人来说,我们在一进入赌场就对每台老虎机扔钱的概率 就有一个先验分布(prior distribution)的假设了,比如一个很常见的我们可以用Beta分布。如果我们认为大概率 都应该是0.5,即对半开,而不太可能出现一些很极端的情况,我们就可以选择Beta(1,1)分布作为我们的先验分布。然后在我们真正摇了老虎机之后,根据相应的反馈,我们就可以调整 们相应的后验分布(posterior distribution)。比如如果某台机器摇了四五次一直吐不出钱,我们就应该将这台机器的吐钱概率的分布往左推,因为它的 大概率应该是小于0.5的。那么,你的任务便是要在有限的时间内找出 后验分布比较靠右的那些机器(因为他们更容易吐钱),并且尽可能多的去摇这些比较赚钱的机器。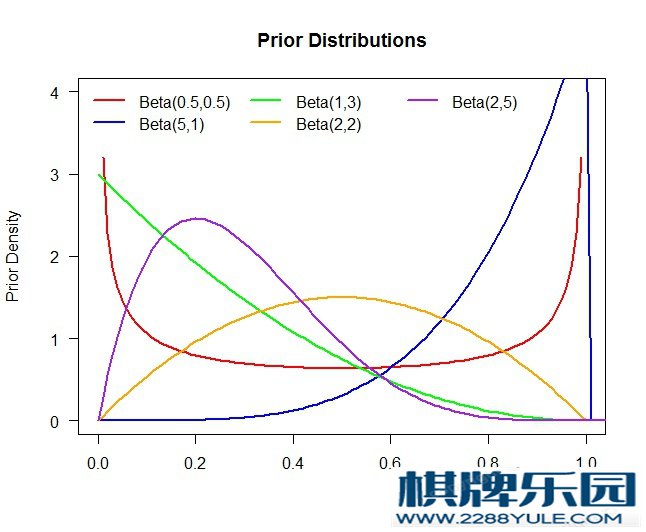
 而如果你是频率学家,就没什么先验或者后验分布了,你假设你一开始对这些机器的吐钱概率一无所知。你认为每个机器的 是个确定的值。那么,你的任务就是要在有限的时间内找到那些高 的机器,并尽可能多的去摇它们,以获得更多的回报。那么这里我们注意到这类问题的一大特点,即我们只有 次摇机器的机会,如何去平衡这 次中exploration(探索)和exploitation(挖掘)的次数。探索意味着广度,比如如果你是频率学家,你一开始什么都不知道,你至少每个机器都需要稍微摇几次(假设
而如果你是频率学家,就没什么先验或者后验分布了,你假设你一开始对这些机器的吐钱概率一无所知。你认为每个机器的 是个确定的值。那么,你的任务就是要在有限的时间内找到那些高 的机器,并尽可能多的去摇它们,以获得更多的回报。那么这里我们注意到这类问题的一大特点,即我们只有 次摇机器的机会,如何去平衡这 次中exploration(探索)和exploitation(挖掘)的次数。探索意味着广度,比如如果你是频率学家,你一开始什么都不知道,你至少每个机器都需要稍微摇几次(假设  ,不然问题就无法搞定了)才能对每个机器吐钱概率有个大概感觉。然后,你可能会缩小你的搜索范围,再几台机器里重点实验,最后可能就专门摇一台你觉得最容易吐钱的机器了。当然,我们之后会看到这种办法也未必是最好的。不过这个回答里我们不谈具体的算法,因此这个问题先抛给大家思考了。本节最后,我们指出这个MAB问题可能的一些(更复杂的)变种。首当其冲的在于,我们前面的讨论默认了环境是不会变化的。而一些MAB问题,这个假设可能不成立,这就好比如果一位玩家发现某个机器的 很高,一直摇之后赌场可能人为降低这台机器吐钱的概率。在这种情况下,MAB问题的环境就是随着时间/玩家的行为会发生变化。这类问题,在合理的假设下,也是有不少研究和相应的算法的。目前做的最多的假设,也就是所谓的adversarial bandit(就不是stochastic bandit了),就是说这些 会被一个“对手”(也可以看成上帝)设定好。如果这是事先设定好,并且在玩家开始有动作之后也无法更改,我们叫做oblivious adversary setting; 如果这个对手在玩家有动作之后还能随时更改自己的设定,那就叫做adaptive adversary setting, 一般要做成zero-sum game了。此外,最近也有一些随机但nonstationary的假设下的工作。 另外MAB有一类很重要的变种,叫做contextual MAB(cMAB)。几乎所有在线广告推送(dynamic ad display)都可以看成是cMAB问题。在这类问题中,每个arm的回报会和当前时段出现的顾客的特征(也就是这里说的context)有关。同样,今天我们不展开讲cMAB,这会在之后花文章专门讨论。另外,如果每台老虎机每天摇的次数有上限,那我们就得到了一个Bandit with Knapsack问题,这类问题以传统组合优化里的背包问题命名,它的研究也和最近不少研究在线背包问题的文章有关,之后我们也会专门讨论。还有很多变种,如Lipshitz bandit, 我们不再有有限台机器,而有无限台(它们的reward function满足利普西茨连续性)等等。。题主既然要最通俗的版本,所以这里就不赘述了,有兴趣深入了解的同学们可以考虑关注我的专栏系列文章,主要是让大家有更好的准备去读一些专门的书籍文献~
,不然问题就无法搞定了)才能对每个机器吐钱概率有个大概感觉。然后,你可能会缩小你的搜索范围,再几台机器里重点实验,最后可能就专门摇一台你觉得最容易吐钱的机器了。当然,我们之后会看到这种办法也未必是最好的。不过这个回答里我们不谈具体的算法,因此这个问题先抛给大家思考了。本节最后,我们指出这个MAB问题可能的一些(更复杂的)变种。首当其冲的在于,我们前面的讨论默认了环境是不会变化的。而一些MAB问题,这个假设可能不成立,这就好比如果一位玩家发现某个机器的 很高,一直摇之后赌场可能人为降低这台机器吐钱的概率。在这种情况下,MAB问题的环境就是随着时间/玩家的行为会发生变化。这类问题,在合理的假设下,也是有不少研究和相应的算法的。目前做的最多的假设,也就是所谓的adversarial bandit(就不是stochastic bandit了),就是说这些 会被一个“对手”(也可以看成上帝)设定好。如果这是事先设定好,并且在玩家开始有动作之后也无法更改,我们叫做oblivious adversary setting; 如果这个对手在玩家有动作之后还能随时更改自己的设定,那就叫做adaptive adversary setting, 一般要做成zero-sum game了。此外,最近也有一些随机但nonstationary的假设下的工作。 另外MAB有一类很重要的变种,叫做contextual MAB(cMAB)。几乎所有在线广告推送(dynamic ad display)都可以看成是cMAB问题。在这类问题中,每个arm的回报会和当前时段出现的顾客的特征(也就是这里说的context)有关。同样,今天我们不展开讲cMAB,这会在之后花文章专门讨论。另外,如果每台老虎机每天摇的次数有上限,那我们就得到了一个Bandit with Knapsack问题,这类问题以传统组合优化里的背包问题命名,它的研究也和最近不少研究在线背包问题的文章有关,之后我们也会专门讨论。还有很多变种,如Lipshitz bandit, 我们不再有有限台机器,而有无限台(它们的reward function满足利普西茨连续性)等等。。题主既然要最通俗的版本,所以这里就不赘述了,有兴趣深入了解的同学们可以考虑关注我的专栏系列文章,主要是让大家有更好的准备去读一些专门的书籍文献~
台老虎机(arms)。我们知道,老虎机本质上就是个运气游戏,我们假设每台老虎机 都有一定概率 吐出一块钱,或者不吐钱( 概率 )。假设你手上只有 枚代币(tokens),而每摇一次老虎机都需要花费一枚代币,也就是说你一共只能摇 次,那么如何做才能使得期望回报(expected reward)最大呢?这就是最经典的MAB场景。那么问题的核心是什么呢?自然,我们应该要假设 们是不太一样的(不然怎么摇都一样了),即有一些老虎机比较“好”(更容易吐钱),有一些则比较“差”(不太容易吐钱)。回到RL的框架,我们的动作是什么?即每次摇哪台老虎机。我们的反馈呢?即我们摇了某台特定的老虎机当回合可以观察它吐了钱没有。这里当然还有个重要的统计学/哲学问题:即我们是贝叶斯人(Bayesian)还是频率学家(frequentist)。对贝叶斯人来说,我们在一进入赌场就对每台老虎机扔钱的概率 就有一个先验分布(prior distribution)的假设了,比如一个很常见的我们可以用Beta分布。如果我们认为大概率 都应该是0.5,即对半开,而不太可能出现一些很极端的情况,我们就可以选择Beta(1,1)分布作为我们的先验分布。然后在我们真正摇了老虎机之后,根据相应的反馈,我们就可以调整 们相应的后验分布(posterior distribution)。比如如果某台机器摇了四五次一直吐不出钱,我们就应该将这台机器的吐钱概率的分布往左推,因为它的 大概率应该是小于0.5的。那么,你的任务便是要在有限的时间内找出 后验分布比较靠右的那些机器(因为他们更容易吐钱),并且尽可能多的去摇这些比较赚钱的机器。而如果你是频率学家,就没什么先验或者后验分布了,你假设你一开始对这些机器的吐钱概率一无所知。你认为每个机器的 是个确定的值。那么,你的任务就是要在有限的时间内找到那些高 的机器,并尽可能多的去摇它们,以获得更多的回报。那么这里我们注意到这类问题的一大特点,即我们只有 次摇机器的机会,如何去平衡这 次中exploration(探索)和exploitation(挖掘)的次数。探索意味着广度,比如如果你是频率学家,你一开始什么都不知道,你至少每个机器都需要稍微摇几次(假设 ,不然问题就无法搞定了)才能对每个机器吐钱概率有个大概感觉。然后,你可能会缩小你的搜索范围,再几台机器里重点实验,最后可能就专门摇一台你觉得最容易吐钱的机器了。当然,我们之后会看到这种办法也未必是最好的。不过这个回答里我们不谈具体的算法,因此这个问题先抛给大家思考了。本节最后,我们指出这个MAB问题可能的一些(更复杂的)变种。首当其冲的在于,我们前面的讨论默认了环境是不会变化的。而一些MAB问题,这个假设可能不成立,这就好比如果一位玩家发现某个机器的 很高,一直摇之后赌场可能人为降低这台机器吐钱的概率。在这种情况下,MAB问题的环境就是随着时间/玩家的行为会发生变化。这类问题,在合理的假设下,也是有不少研究和相应的算法的。目前做的最多的假设,也就是所谓的adversarial bandit(就不是stochastic bandit了),就是说这些 会被一个“对手”(也可以看成上帝)设定好。如果这是事先设定好,并且在玩家开始有动作之后也无法更改,我们叫做oblivious adversary setting; 如果这个对手在玩家有动作之后还能随时更改自己的设定,那就叫做adaptive adversary setting, 一般要做成zero-sum game了。此外,最近也有一些随机但nonstationary的假设下的工作。 另外MAB有一类很重要的变种,叫做contextual MAB(cMAB)。几乎所有在线广告推送(dynamic ad display)都可以看成是cMAB问题。在这类问题中,每个arm的回报会和当前时段出现的顾客的特征(也就是这里说的context)有关。同样,今天我们不展开讲cMAB,这会在之后花文章专门讨论。另外,如果每台老虎机每天摇的次数有上限,那我们就得到了一个Bandit with Knapsack问题,这类问题以传统组合优化里的背包问题命名,它的研究也和最近不少研究在线背包问题的文章有关,之后我们也会专门讨论。还有很多变种,如Lipshitz bandit, 我们不再有有限台机器,而有无限台(它们的reward function满足利普西茨连续性)等等。。题主既然要最通俗的版本,所以这里就不赘述了,有兴趣深入了解的同学们可以考虑关注我的专栏系列文章,主要是让大家有更好的准备去读一些专门的书籍文献~
到后期对手如果已经胡牌了,例如对手胡牌的是4万棋牌问答,这个时候按照常规的胡牌的规则可以看出来对家可能会需要1万或者是7万,因为胡四万的线万一定要慎重的出牌。(当然这些只是一般的情况)


